홈 IoT 제작 – 대중교통편 (2) 설계
설계를 위한 배경
이전 글( 홈 IoT 제작 – 대중교통편 (1) ) 에 이어서 설계 및 구현 내용을 작성해보고자 한다.
설계에 앞서 내가 이용할 외부데이터를 정리해보았다. 버스 도착정보와 지하철 열차 시간표가 필요했다.
버스의 경우 내 거주지역이 경기도이므로 경기버스 (http://gbis.go.kr) 에서 찾아보기로 했다.

테스트용 값이나 테스트를 위한 데이터를 받아오는 것은 가능했지만 오픈 API를 이용하기 위해서는 다른 기관을 이용해 접근해야했다.

이제는 당연한 이야기지만 공공데이터 활용을 위한 개발 API신청은 공공데이터 포털(http://data.go.kr)을 이용해야한다.
이 과정은 매우 단순한데, 그래도 별도의 항목으로 추후 작성하도록 한다.
설계 – 버스
아무튼, 키를 발급했고, 요청시 응답받은 데이터를 파싱해야 하므로 테스트 데이터가 어떻게 날라오나 확인해보았다. 공공데이터 포털에서 제공하는 명세가 있으나 가독성이 너무 떨어져 그냥 날라오는 데이터를 직접 보기로 했다. xml형태의 데이터가 날라오는 것을 볼 수 있다.
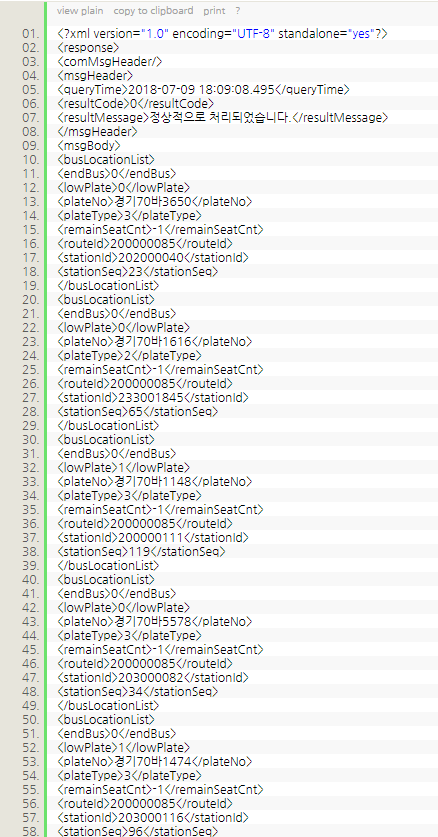
요청시 필요한 파라미터는 서비스 API마다 다른데, 기본적으로 필수로 던져야 하는 것은 serviceKey 이다. 여기에는 발급받은 API 키를 담으면 된다. 그 뒤에는 서비스 별로 노선번호나 정류장번호, 혹은 주변위치 좌표 등을 담아 전송하면 xml데이터를 담은 응답이 온다.
응답 xml데이터에는 크게 3개의 섹션으로 구분되어 있는데, comMsgHeader, msgHeader, msgBody로 나뉜다.
먼저 comMsgHeader는 요청, 응답 자체에 대한(HTTP) 결과 정보를 담는다.
다음으로 msgHeader는 API서비스에 대한 결과 정보를를 담는다.
2개의 큰 차이는 다음과 같은 예를 들면 쉽게 이해할 수 있다.
올바른 API주소로 요청을 날렸으나, serviceKey를 올바르게 입력하지 않았을 경우, comMsgHeader에는 정상적인 요청 및 응답이 날라왔다고 하지만 msgHeader는 등록되지 않은 서비스키라고 답해준다.
마지막으로 msgBody는 우리가 원하는 데이터가 담겨져 있다. 이 데이터를 파싱하여 운영환경에 적용할 수 있도록 가공하면 된다.
모든 버스 데이터는 필요없고 주요 경로를 다니는 버스정보만 필요하므로 나에게 필요한 노선 ID만 파싱할 계획이다. 그런데 내 거주지에 한 가지 단점이자 장점인 사항이 있는데, 지나다니는 전체 버스중 몇 노선이 집 바로 근처에서 출발하는(정확하게는 회차점) 노선이 문제의 핵심이다.
직행이나 좌석버스는 앉아서 가기 좋아 장점인줄만 알았는데, 언제 나오는지는 알리미를 제작하여도 미리 알 수가 없다는 단점이 있었다.
하지만 이 문제도 쉽게 간파할 수 있었던 것은 차고지나 회차점으로 한 대가 들어가면 쉬고있던 다른 버스 한대가 나온다는 규칙이 있다는 점에 있었다.
이 덕분에 회차점이나 회차점 직전의 정류소의 도착정보를 추가로 가져와 집 앞의 해당 노선의 데이터가 없을 시 데이터 보정을 이룰 수 있었다.
설계 – 전철
이전에 네이버 전철시간표를 크롤링하는 크롤러를 만든적이 있는데, 아무리 찾아도 스크립트 파일이 나오지 않아 다시 짜야할 것 같다.
우선 전철 알리미는 2가지 방식을 동시에 제공하려고 한다. 하나는 남은 시간이고, 다른 하나는 몇 전인지 알려주는 것이다.
전자는 정~~말 쉽다. 후자도 물론 쉽지만 DB접근 최소화를 위해 약간 꼼수를 써야했다.
남은 시간이야 정렬된 시간표에서 현재 시간보다 늦은 시각의 첫번째 시간표를 가져오면 되는 문제이지만, 몇 전인지는 실제로 열차정보를 가져오지 않으면 정확하게 알 수 없어 역간 이동 시간으로 추측해야하나 싶었다.
그러던 중 역 하나 말고 n전 역들의 시간표까지 가져와 daisy chain으로 역참조를 하면 쉽게 해결될 문제라고 생각했다. 물론 단순히 전역 정보가져오고 비교하고 다시 이전역 정보를 가져오고 비교하고를 반복하면 DB접근 횟수가 쓸데없이 많아지므로 SQL을 최적화해서 사용하려고 한다.
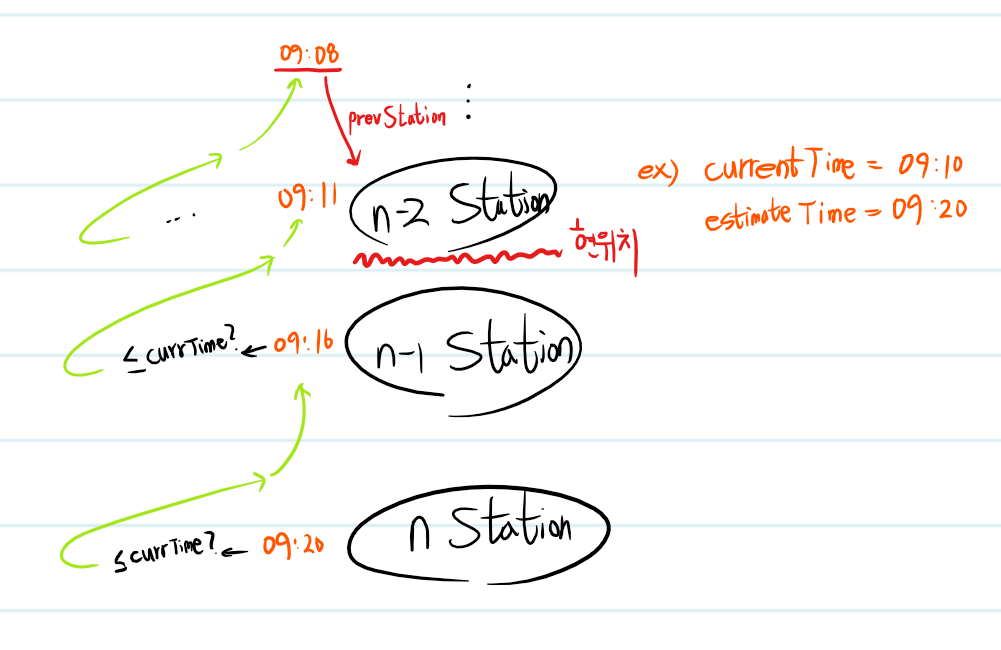
대충 도표로 나타내면 위와같다. 먼저 기준 역의 시간과 현재시간을 비교한 뒤, 현재 시간이 빠르면 n-1역의 시간표와 다시 비교한다.
이 작업을 현재 시간보다 역 도착시간이 빠를때까지 반복한다. 도착시간이 빠르다는건 해당 역을 통과했다는 뜻이니 현재 열차의 위치를 해당 역의 다음 역으로 추론할 수 있다.
그 위에 문단에 적은대로 이 계산을 위해 한 row씩 비교하면 좋은 성능을 기대할 수 없다. 간단한 프로젝트라도 좋지 않은 습관을 들일 필요는 없다. SQL구문을 최대한 활용하면, 호스트언어의 for loop를 최소화하고 계산할 수 있다.
WHERE문에서 현재 시간보다 낮은 시간표를 가져오도록 하고, GROUP BY문에서 역별로 그룹을 짓도록 한다면 위에 daisy체인에 해당하는 모든 역의 row들을 받아오리라 예상된다. // 다만 이 작업은 임시로 쓰고있는 sqlite에서는 표현이 힘드므로 현재는 n회에 걸친 select문을 이용한다..
이 작업을 위해서는 평일 및 주말의 역별 시간표를 보관해야한다. 네이버에서 지원하는 전철 시간표의 도움을 받아 시간표를 크롤링 정리한다.
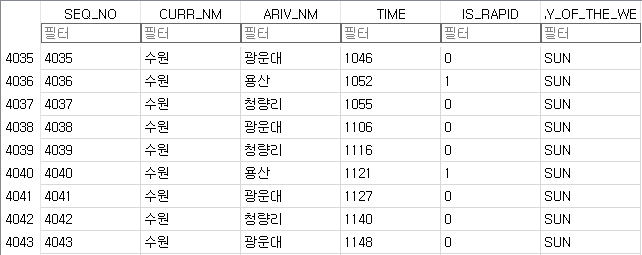
위에는 시간표를 크롤링 정리한 결과 예시인데 위의 로직에서 정렬된 타임테이블이 필요하기때문에 row number에 해당하는 SEQ_NO 칼럼을 추가했다.
SQL은 아직 수정중에 있어 따로 업로드하지는 않고, 1차적으로 출력된 결과는 아래와 같다.
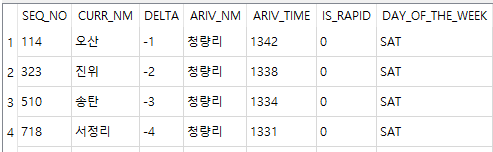
SQL을 조금 더 다듬고, 시리얼통신으로 아두이노에 전송하려고 한다.
100개의 댓글